List
可重复集合List,是有序的Collection,有三个实现类
1 ArrayList 底层使用数组实现,增删慢,查找快,线程不安全。
2 LinkedList 基于双向链表,增删快,查找慢,线程不安全。提供了更多的方法用于操作头部和尾部,可以被当做栈,队列或双向队列。还实现了Deque接口。
3 Vector 基于数组实现,支持线程同步,同一时刻只允许一个线程对Vector进行 写 操作,整体效率比ArrayList低。
ArrayList的扩容机制
- 计算所需容量,若原来的数组为空,则所需容量最少为10
- 判断是否需要扩容,若所需容量不大于当前容量,则不扩容。
- 计算默认目标容量,默认为1.5倍(通过移位计算)
- 若所需容量大于原容量的1.5倍,则目标容量为所需容量。
- 若目标容量大于最大数组容量MAX_INT - 8 :(若所需容量在MAX_INT - 8 ~ MAX_INT 范围内,则目标容量为int最大值,若小于此范围,则使用最大数组容量,若所需容量为负,即溢出,则抛出OOMError)
- 拷贝数组
计算所需容量,若原来的数组为空,则所需容量最少为10
1 | private void ensureCapacityInternal(int minCapacity) { |
判断是否需要扩容,若所需容量不大于当前容量,则不扩容。
1 | private void ensureExplicitCapacity(int minCapacity) { |
扩容:
1 | private void grow(int minCapacity) { |
Queue
Queue是队列结构,常用队列如下:
- ArrayBlockigQueue:基于数组实现的有界阻塞队列
- LinkedBlockingQueue:基于链表实现的有界阻塞队列
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列
- DelayQueue:支持延迟操作的无界阻塞队列
- SynchronousQueue:用于线程同步的阻塞队列
- LinkedTransferQueue:基于链表实现的无界阻塞队列
- LinkedBlockingDeque:基于链表实现的双向阻塞队列
阻塞队列的操作:
put 添加一个元素 如果队列满,则阻塞
take 移除并返回队列头部的元素 如果队列为空,则阻塞
队列的操作可以根据它们的响应方式分为以下三类:add、remove和element操作,在你试图为一个已满的队列增加元素或从空队列取得元素时抛出异常。当然,在多线程程序中,队列在任何时间都可能变成满的或空的,所以你可能想使用offer、poll、peek方法。这些方法在无法完成任务时 只是给出一个出错示而不会抛出异常。
poll和peek方法出错进返回null。因此,向队列中插入null值是不合法的

LinkedBlockingQueue的容量默认为Integer.MAX_VALUE,,可以选择指定其最大容量,基于链表,按 FIFO(先进先出)排序元素。
LinkedBlockingQueue实现的队列中的锁是分离的,即生产用的是putLock,消费是takeLock。在生产和消费的时候,需要把枚举对象转换为Node
ArrayBlockingQueue在构造时需要指定容量,可选是否需要公平性,如果公平参数被设置true,等待时间最长的线程会优先得到处理(其实就是通过将ReentrantLock设置为true来 达到这种公平性的:即等待时间最长的线程会先操作)。通常,公平性会使你在性能上付出代价,只有在的确非常需要的时候再使用它。它是基于数组的阻塞循环队 列,此队列按 FIFO(先进先出)原则对元素进行排序。采用可重入锁ReentrantLock+Condition来实现线程并发的
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁,在生产和消费的时候,是直接将枚举对象插入或移除的。初始化必须指定队列的大小。
PriorityBlockingQueue是一个带优先级的队列,而不是先进先出队列。元素按优先级顺序被移除,该队列也没有上限(看了一下源码,PriorityBlockingQueue是对 PriorityQueue的再次包装,是基于堆数据结构的,而PriorityQueue是没有容量限制的,与ArrayList一样,所以在优先阻塞 队列上put时是不会受阻的。虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError),但是如果队列为空,那么取元素的操作take就会阻塞,所以它的检索操作take是受阻的。另外,往入该队列中的元 素要具有比较能力。传入的对象必须实现comparable接口。
DelayQueue(基于PriorityQueue来实现的)是一个存放Delayed 元素(需要实现Delayed接口)的无界阻塞队列,只有在延迟期满时才能从中提取元素。该队列的头部是延迟期满后保存时间最长的 Delayed 元素。如果延迟都还没有期满,则队列没有头部,并且poll将返回null。当一个元素的 getDelay(TimeUnit.NANOSECONDS) 方法返回一个小于或等于零的值时,则出现期满,poll就以移除这个元素了。此队列不允许使用 null 元素。
SynchronousQueue是一个内部只能包含一个元素的队列。插入元素到队列的线程被阻塞,直到另一个线程从队列中获取了队列中存储的元素。同样,如果线程尝试获取元素并且当前不存在任何元素,则该线程将被阻塞,直到线程将元素插入队列。
其他详情见并发编程
Set
不可重复集合,根据hashCode和equals判断是否相同
1 HashSet 内部使用HashMap存储,HashMap中的Value存放的是:
1 | private static final Object PRESENT = new Object(); |
2 TreeSet 内部使用TreeMap存储。TreeMap内部使用红黑树。
3 LinkHashSet 内部使用LinkedHashMap存储。大部分方法直接调用父类
Map
键值对 类型的集合
1 HashMap
允许 key,value为null。是非线程安全的。多个线程同事修改有可能导致循环链表-死循环。有需要可以使用ConcurrentHashMap。
存储结构
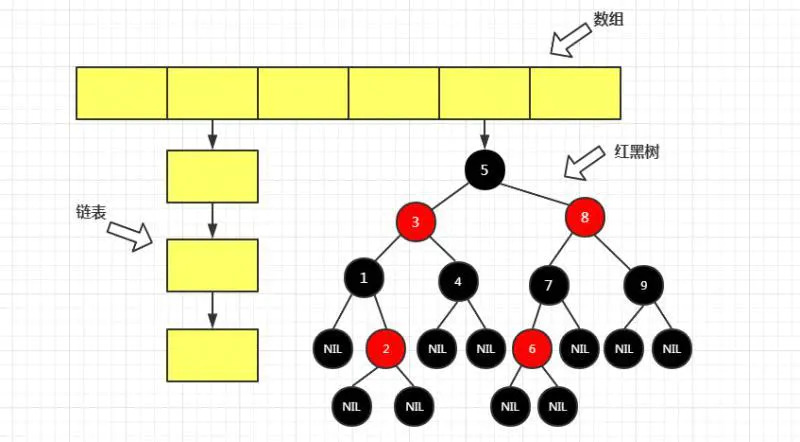
内部是一个数组,在1.8以前,每个数组元素都是一个单项链表。链表每个元素都是Entry。
1.8开始,在链表长度达到7时(bingCount >= TREEIFY_THRESHOLD - 1),并且hash tab[]数组长度大于等于64时,将链表转换成红黑树,如果数组长度小于64,只是对数组进行扩容。红黑树查询时间复杂度为 O(logn),且平衡代价低。
四种构造函数
1默认 2指定容量 3 指定容量(抛出参数错误)4传入一个map
tableSizeFor()
返回的是大于当前传入值的最小(最接近当前值)的一个2的n次幂的值。保证了Table的长度为2的n次幂
获取元素
1 判断key是否空
2 查找数组索引第一个元素是否为key,是则返回
3 判断key是否为红黑树,是则调用红黑树查找方法
4 遍历查询链表
5 找不到,返回null
放入元素
1 table[]是否为空,若为空则创建(resize)
2 判断table[i]处是否插入过值,若没有则直接放入kv新节点
3 判断table[i]的key是否为输入key,是则替换value
3 判断table[i]是否为红黑树,是则直接调用插入树的方法
4 判断key是否和原有key相同,如果相同就覆盖原有key的value,并返回原有value
5 如果key不存在,就插入一个key,记录结构变化一次
size > 阈值, resize
hash()计算原理
先计算key的hashCode值,赋值给h,然后把h右移16位,并与原来的h进行异或处理
如何寻找下标
i = (length - 1) & hash,本应是 hash % n ,但是由于length一定是2的n次幂,所以,使用位运算取余更快。
HashMap常用变量:
- capacity 当前数组容量。默认为16,可扩容,扩容后大小为原来的两倍。
- loadFactor 负载因子,默认为0.75
- threshold 扩容阀值,其值为 容量 x 负载因子
确定元素在数组中的位置
1 | //方法一: |
记录结构变化次数
如下3种情况,例子需要自己调式,主要关注数组长度(OldCap,newCap)新老变化,扩容阈值(oldThr,newThr)新老变化
1 | //① |
1 | if ((tab = table) == null || (n = tab.length) == 0) |
第一次的时候,数组长度为默认值16,阈值为16*0.75=12,等到数组长度超过阈值12后,触发第二次扩容,此时table数组,和threshold都不为0,即oldTab、oldCap、oldThr都不为0,如果oldCap长度的2倍没有超过最大容量,并且oldCap 长度大于等于 默认容量16,那么下次扩容的阈值 变为oldThr大小的两倍即 12 * 2 = 24,newThr = 24,newCap=32
② 设置了initialCapacity,没有设置负载因子,此时hashMap使用默认负载因子0.75,本实例设置的初始容量为2,通过计算阈值为2,第一次put的时候由于还没初始化table数组,因此触发第一次扩容。此时oldCap为0,oldThr为2,确定这次扩容的新数组大小为2,此时还没有确定newThr 下次扩容的大小, 确定newThr为 2 * 0.75 = 1.5 取整 1 ,及下次扩容阈值为1。当数组已有元素大于阈值及1时,触发第二次扩容,此时oldCap为1,oldThr为1,newCap = oldCap << 1 结果为 4 小于最大容量, 但oldCap 小于hashMap默认大小16,结果为false,跳出判断,此时由于newThr等于0,确定newThr为 4 * 0.75 = 3,下次扩容阈值为3
③ 设置了initialCapacity=2,负载因子为0.5,通过tableSizeFor计算阈值为2,第一次put的时候,进行扩容,此时oldCap为2,oldThr为2,同实例②,newCap = oldCap << 1 结果为 4 小于最大容量, 但oldCap 小于hashMap默认大小16,结果为false,跳出判断,确定newThr为 4 * 0.5 = 2,下次扩容阈值为2